Architecting an AI solution on AWS serverless
Motivation
My motivation for this article is threefold. First, I want to share my experience developing an AI system using only AWS serverless components. Secondly, I want to share the general performance of AWS Lambda in terms of running a CPU-intensive AI solver developed with Quarkus Native. And thirdly, I want to share my experience in developing all the infrastructure as code using CloudFormation and automating all CI/CD with GitHub Actions.
Project link: https://joaopedroschmitt.click
Vehicle Routing Problem
The vehicle routing problem (VRP) is a combinatorial optimization problem which asks “What is the optimal set of routes for a fleet of vehicles to traverse in order to deliver goods to a given set of customers?” $^1$. In general, VRP appears in real-life scenarios like those challenged by logistic companies (DHL, Kuehne + Nagel, Fedex), delivery apps (Uber Eats, Glovo), and dial-a-ride companies (Uder, Taxi99, Bolt).
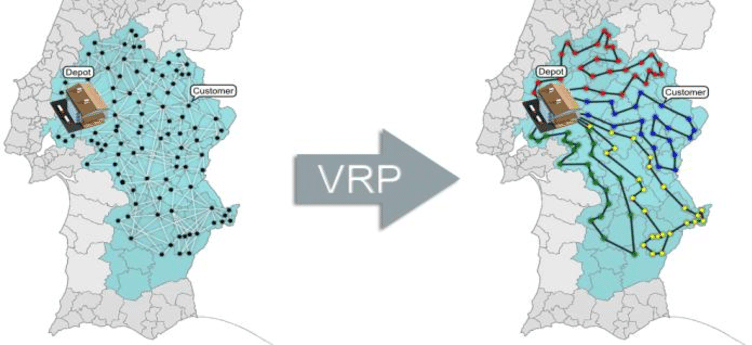
The image below depicts the main VRP goal. On the left we have the problem input, a set of customers spread across the map that have requested goods to be picked up and delivered from a company’s depot. On the right we have an example of output, the solution for the problem. It consists of a set of routes (a.k.a. itineraries), to be followed by a fleet of vehicles, so all goods are delivered to customers on time. The main VRP challenge is about finding the best itineraries to minimize (or maximize) a specific business KPI (e.g.: total travel time, total gas consumption, total delays, profit, etc) $^2$.
Why is Vehicle Routing Problem hard solve?
Imagine you want to build all possible words using only three letters A, B, and R. In this scenario you would permutate ABC in all possible ways (ABR, ARB, BAR, BRA, RAB, and RBA) and pick only valid words (BAR). Now, as more letters we add, more possible combinations exist. The number of combinations grows exponentially in function of the number of letters. For example, if we try to build all valid words using 26 letters, we would have 403291461126605635584000000 different words. Suppose a ordinary computer takes one nanosecond to build and validate each word. In this scenario the computer would require at least 127882883 centuries to finish the task completely. Now talking abou the challenge with VRP is that it’s framable in this word building model. If we face each letter as a customer’s order and each word as a possible itinerary solution, we end up with and intractable problem in terms of finding the best solution in a one’s lifetime.
There are many ways to tackle VRP. The most common ones involve the application of exact and heuristic algorithms. Exact algorithms try to build all possible solutions by avoiding combinations that lead to invalid solutions in such a way to save time. Heuristic algorithms use contextual knowledge to guide the algorithm on building promissing solutions that solve the problem, sometimes allowing to build invalid temporary solutions. Depending on the number of “valid” solutions your problem has, one method can be better than the other. Usually heuristic methods tend to perform better in problems with a high number of “valid” solutions.
For many reasons not discussed in this article, we’ve chosen to implement an AI solver based on the Adaptive-Large Neighborhood Search heuristic (ALNS for short). For the sake of this article, we’ll refer to this ALNS implementation as “solver” for simplicity. Solvers are CPU-intensive tasks because they do heavy computations to search for the optimal solution. And because they are very CPU-intensive tasks, one of the motivations for this work is to assess how AWS serverless components perform with this kind of workloads.
Logical Design
First of all, this section presents the logical flow of the solution before I start digging deep into the technical details. The following sequence diagram shows the most common use case, a user creating a route and requesting the solver to generate the best itinerary possible. The diagram contains all microservices (the top 7 boxes) and presents all system interactions highlighted in red. The subsequent subsections discuss in details each of these steps.
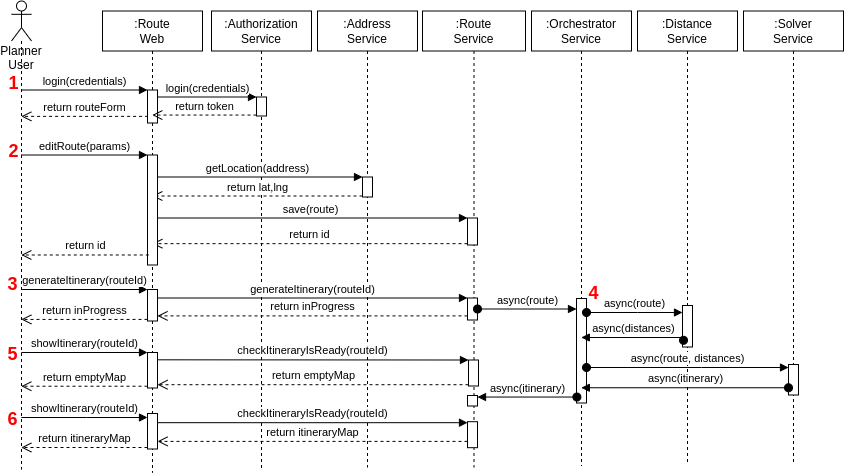
Step 1
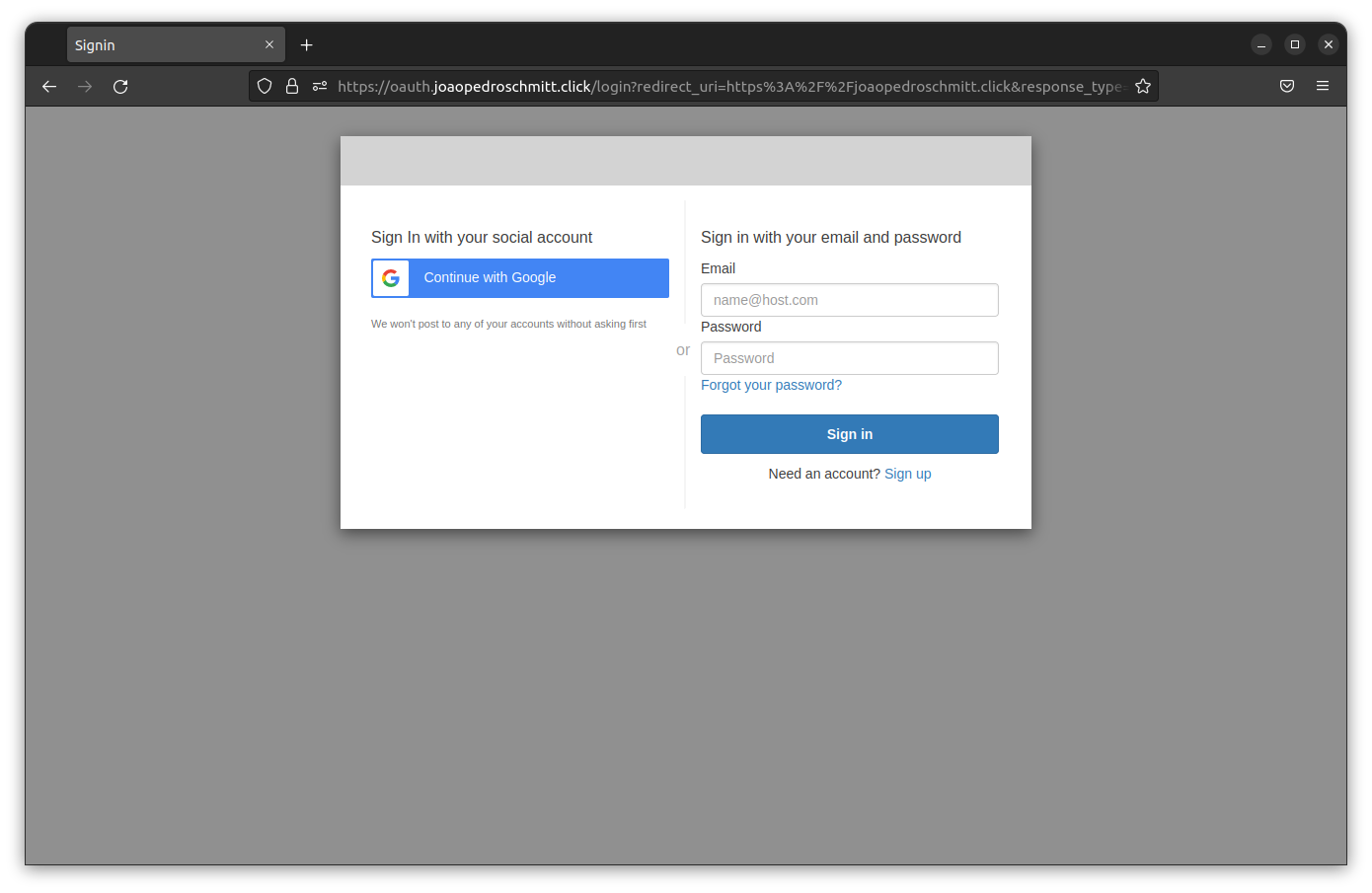
The end-to-end flow begins with the user logging in the application.
Given the user credentials, the application decides if the routeForm web page is presented or not.
Step 2
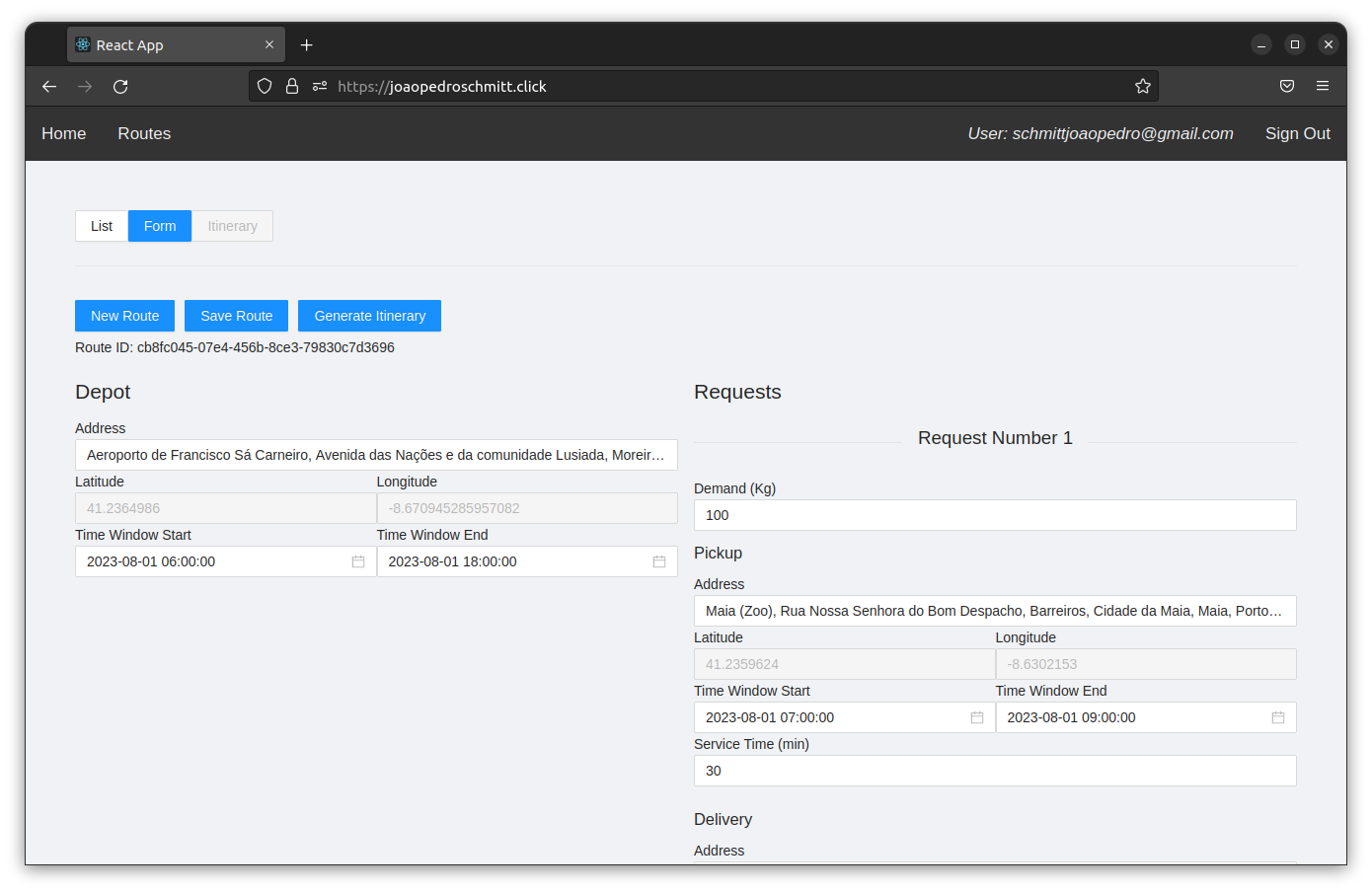
In the second step, the user edits a route.
In the RouteWeb web page, the user configures the depot params (location and attendance time window) and adds various customer requests (product pickup location, delivery location, attendance time window, weight, and service time).
The RouteWeb front-end calls the AddressService to fetch the latitude and longitude for each location during the recording.
When the user finally cliks on the save button, the RouteWeb front-end calls the RouteService to persist the route in the database.
Step 3
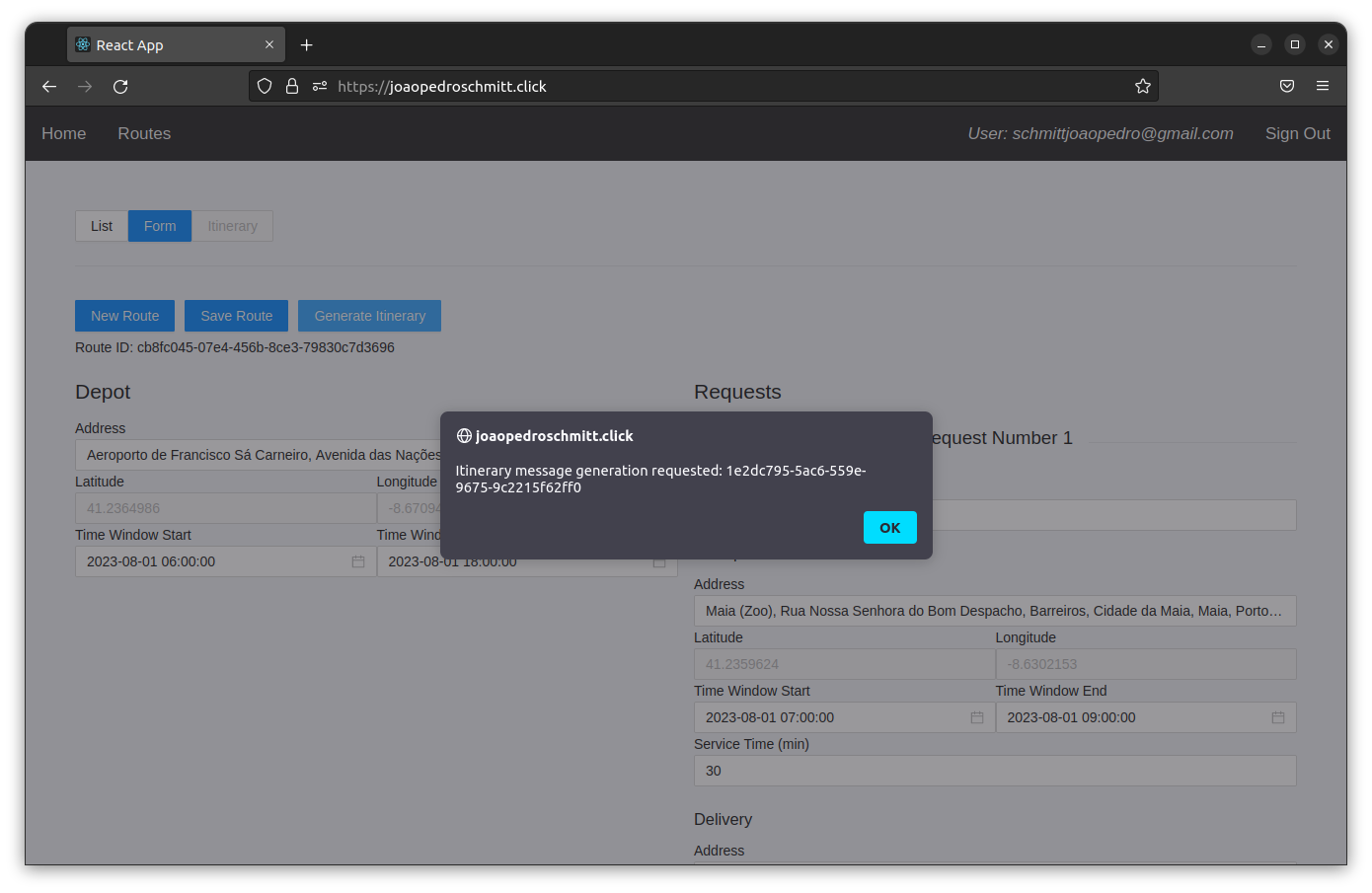
In the third step the user clicks on “Generate Itinerary” so that RouteWeb front-end calls the RouteService to request the itinerary generation.
Because this process can take some time to finish, RouteService gathers all information recorded in Step 2 and asynchronously calls the OrchestratorService to generate an itinerary through messaging.
At this stage a response is sent back to the user informing the generation is InProgress.
Step 4
In the fourth step the OrchestratorService implements the Orchestrator design pattern and coordinates all necessary tasks to generate an itinerary.
First, the OrchestratoService requests the DistanceService to calculate the distance matrix between all locations asynchronously.
Next, the OrchestratorService calls the SolverService asynchronously passing the route and the distance matrix as parameters to generate the itinerary.
When the OrchestratorService receives back the itinerary from SolverService, it saves this information in a shared storage where the RouteService can query the itinerary and present it to the end user.
Step 5
In case a user requests to see the itinerary before it has been generated, a blank map is shown.
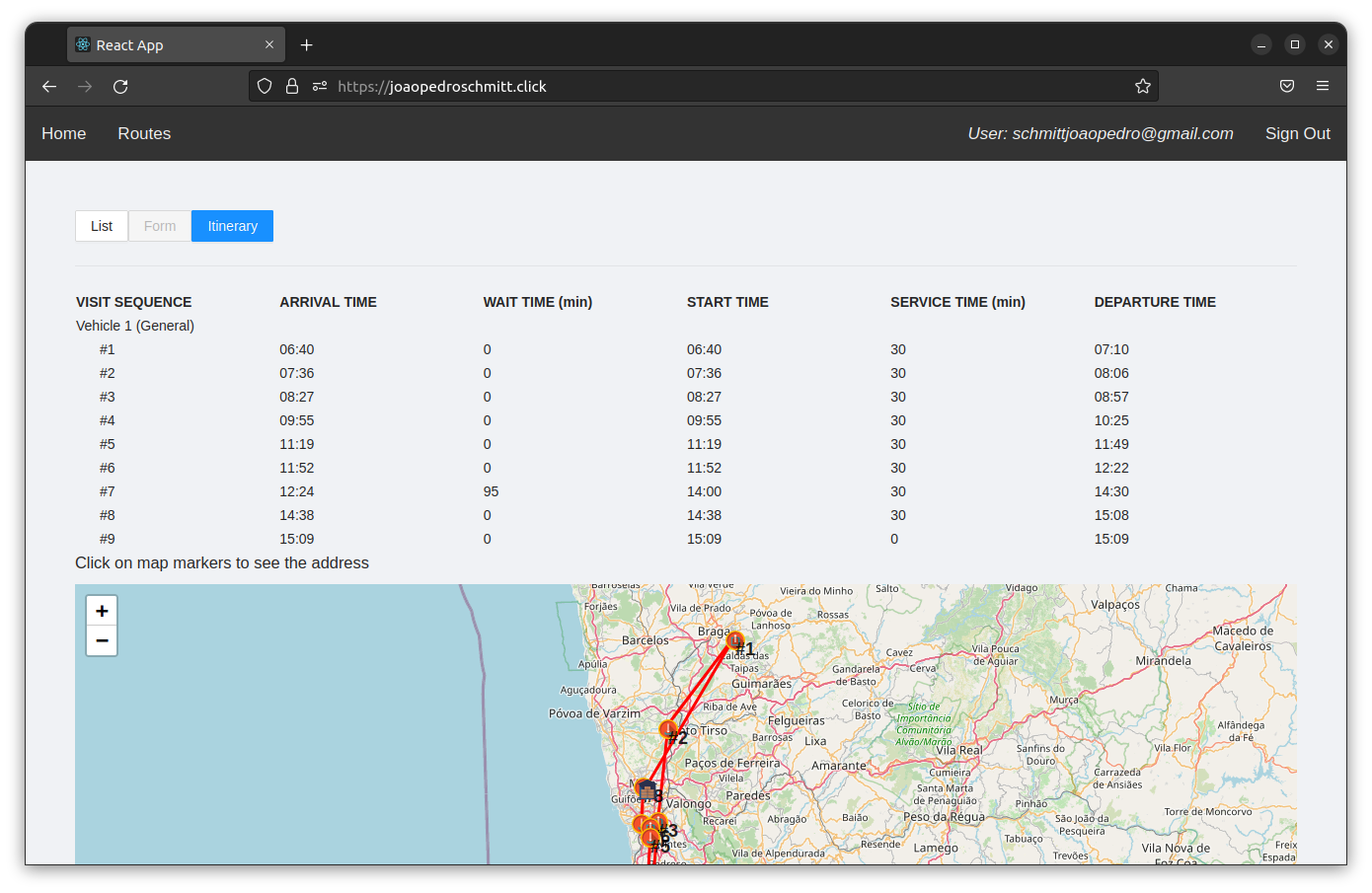
Step 6
In case the user requests to see the itinerary after it has been generated, then the itinerary times are presented on a table and the routing is drawn on a map.
AWS Serverless
Now that the general view of end-to-end flow was presented in the previous section, I can start digging deep into the technical details. I chose for the serverless architecture due to its facility to scale and cost efficiency (pay for what you use). However, designing for serverless requires us to take into considerations a few aspects:
- Lambda serverless workloads are ephemeral and stateless. Therefore the solution has to be designed not to store state information in Lamba’s disk because they are eventually erased by AWS.
- The solution cannot rely on Lambda’s OS architecture. Therefore the configuration space is limited in terms of file system, OS libs and features.
- Lambda functions are intended to be small. Lambda’s lifetime is short and not recommended for long-running applications. It means you can’t benefit much of caching internal transactional state.
- Lambda Idle CPU time has to be minimized. It’s a good idea to avoid many external synchronous integrations as it puts the CPU in idle state. When a Lambda function is idle, waiting for a synchronous response, new requests start new Lambda instances. This effect can reduce service availability if the maximum number of parallel Lambda functions is reached.
- Asynchronous processing through events is generally a good fit. This way Lambda functions are decoupled from waiting for a response and it creates room for new requests to come in.
- In terms of security, make sure that each lambda function have their own unique role so that the principle of the least privilege applies.
- In terms of performance, one of the most important metrics is the startup time of the service to prevent cold start issues and unecessary scaling.
Serverless components
For each microservice, the following diagram presents the components selected and how they were organized.
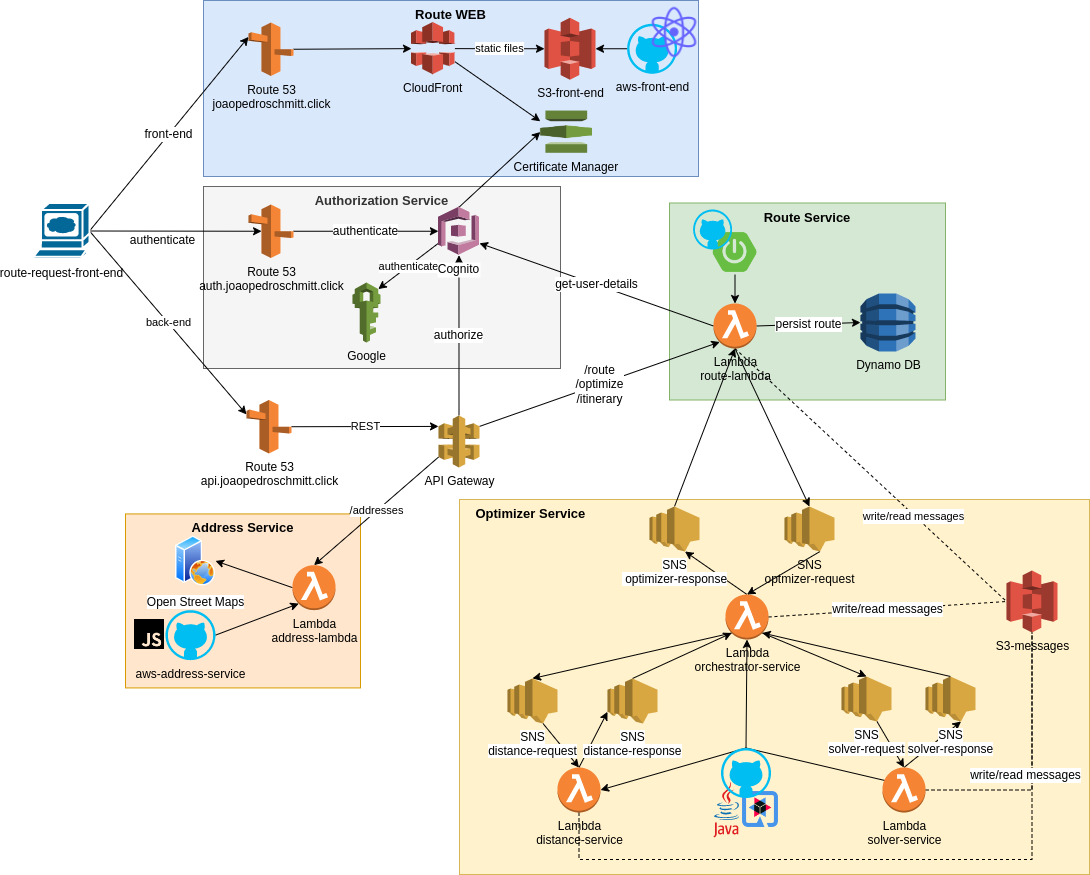
For the RouteWeb front-end I chose S3 and CloudFront to enable fine-grained control on how AWS distributes static content.
As development framework it was decided to use React and AWS Amplifier libs.
For the AuthorizationService it was decided to used Cognito because it enables a smooth integration with external identity providers like Google. Besides that, Cognito also provides simple sign-up/sign-in front-end and an OAuth REST API (used to integrate with other services when needed authoring data for auditing purposes).
For the AddressService was decided to use a simple JavaScript lambda function to fetch addresses’ details (e.g.: latitude and longitude) from OpenStreetMap via REST and transform the response to a readable JSON for the RouteWeb front-end.
For the RouteService I decided on Spring boot so I could reuse some old source code from another project and save some development time.
However, I decided on migrating the database to the serverless DynamoDB option and save some costs with AWS.
By the time the decision on Spring Boot was made, I was aware about the issues on cold-start between standard Spring Boot and Lambda.
For the OptimizerService a few tweaks had to be made.
First, I decided to use Quarkus Native due to its low startup time and low memory consumption.
Secondly, I decided on SNS and S3 as the messaging system because SNS doesn’t require Lambda functions to keep polling for messages (not incurring extra costs), and I had to combine SNS with S3 because messages can be larger than 256kb.
The way the messaging work is by storing then in S3 and using SNS to notify other services when a message is ready to be consumed.
Finally, for the SolverService the Lambda function was configured to have 1.7GB of memory and enable a full CPU for the solver (because the solver is a very CPU-intensive task).
Besides that, the Lambda function timeout was set to 15 minutes so the solver has enough time to find the best itinerary possible for the route being optimized.
Implementation Details
This section highlights the most important architectural decisions taken so far for this project. I focus on a small representation of the decisions and the reasoning behind them. All details and lines of codes are not scrutinized for the sake of readability of this post.
Infrastructure-as-code (IaC)
One of the importantest decisions in terms of maintenance was the ability to store all infrastructure as code. One motivation was to save costs, because IaC enables you to delete and re-create everything as you wish. During certain times when I wasn’t so focused on developing this solution, I used to drop everything for weeks to save some money. However, a more technical grounded reasoning for IaC is that it enables you to have clear documentation and versioning control of all infrastructure decisions taken along the way.
CloudFormation was the technology chosen for this project. It was a vendor lock-in decision because all components used are specific from AWS. The main benefit is the proximity to AWS documentation, and on my personal opinion, the CloudFormation YAML format is easier to understand than other popular like the one from Terraform.
In terms of IaC structure, parts of the infrastructure were grouped per domain in their own stack files to simplify the maintenance. The table below enumerates all stack files, their components, and their logical execution sequence for creating the infrastructure. The sequence is defined based on stack dependencies. The first stack files execute sooner so they can export values and set up the services used by other stacks further down in the execution chain.
| Sequence | Stack File | Description |
|---|---|---|
| 1 | Github | Creates OIDC Provider to enable GitHub Actions integration with AWS to run the pipelines |
| 2 | Params | Creates base params on SSM, for example: - Google OAuth clientID and secrets - HTTPS certificate ARN - DNS domain names. |
| 3 | Base | Creates the following S3 buckets: - Bucket for Lambda startup with a sample blank application - Bucket to store the optimizer SNS messages |
| 4 | Front-end | Creates the front-end S3 bucket, CDN, and Route53 records |
| 5 | Authorization | Creates Cognito user pool, identity provider with Google, OAuth authorization endpoint, user pool client, sign-up/sign-in form |
| 6 | Address | Creates the address service components, like: lambda function, roles, aliases, and the API Gateway routes and authorizers |
| 7 | Routes | Creates the routes service components, like: lambda function, roles, aliases, the API Gateway routes and authorizers, and the DynamoDB table |
| 8 | API domains | Creates the api.joaopedroschmitt.click Route53 record to the API gateways from Address and Routes services |
| 9 | Optimizer | Creates the optimizer lambda functions and roles, SNS topics and permissions |
GitHub Actions
For this project, it is applied a multi-repository approach with five repositories.
The repositories are aws-cloud-infrastructure, aws-address-service, aws-front-end, aws-route-lambda, and aws-route-optimizer.
With respect to aws-route-optimizer, in this specific case, the repository is a mono-repo managing three microservices (OrchestratorService, DistanceService and SolverService) because they share some logical domain and the same Quarkus Native infrastructure.
Besides that, thanks to WebIdentity role configuration in IAM, it was possible to integrate GitHub Actions to AWS by creating an OIDCProvider to enable CI/CD directly to AWS.
The snippet below presents how the integration between GitHub and AWS was set up.
AWSTemplateFormatVersion: 2010-09-09
Description: 'Cloudformation for GitHub actions integration'
Resources:
IDCProvider:
Type: AWS::IAM::OIDCProvider
Properties:
Url: "https://token.actions.githubusercontent.com"
ClientIdList:
- "sts.amazonaws.com"
ThumbprintList:
- 6938fd4d98bab03faadb97b34396831e3780aea1
GitHubIAMRole:
Type: AWS::IAM::Role
Properties:
RoleName: GithubActionsDeployRole
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Action: sts:AssumeRoleWithWebIdentity
Principal:
Federated: !Ref IDCProvider
Condition:
ForAnyValue:StringLike:
token.actions.githubusercontent.com:sub:
- !Sub repo:<GitHub account>/aws-cloud-infrastructure:*
- !Sub repo:<GitHub account>/aws-front-end:*
- !Sub repo:<GitHub account>/aws-address-service:*
- !Sub repo:<GitHub account>/aws-route-optimizer:*
- !Sub repo:<GitHub account>/aws-route-lambda:*
MaxSessionDuration: 3600
Description: "Github Actions role"
Policies:
- PolicyName: 'GithubActionsDeployRole-policy'
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action: '*'
Resource: '*'
I configured the GitHub Action workflows by creating a .github/workflows/deploy.yaml file for each repository.
All files contain the following base structure, and then they are specialized with their own specific build steps accordingly to their tech-stack.
name: <repository name>
on:
push:
branches: [main, master]
workflow_dispatch:
env:
AWS_ROLE: arn:aws:iam::000000000000:role/GithubActionsDeployRole
AWS_REGION: <region>
CI: false
jobs:
build:
name: Build
runs-on: ubuntu-20.04
permissions:
id-token: write
contents: read
steps:
- name: Checkout Repository
uses: actions/checkout@v3
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
role-to-assume: ${{ env.AWS_ROLE }}
role-session-name: GitHub-Action-Role
aws-region: ${{ env.AWS_REGION }}
- name: build steps specific for each project
Each repository is configured to respond to code changes so that every push to GitHub triggers the workflow process.
In this project, the aws-cloud-infrastructure repository was configured to work as the main repository, it creates all the infrastructure and has the capability to fire downstream repositories in a way I can deploy the whole solution with a single click.
The following code snippet from aws-cloud-infrastructure shows how downstream repositories are triggered.
In this example, when route-stack changes (when CHANGES_APPLIED == '1'), it triggers the downstream aws-route-lambda workflow to deploy it’s service.
...
jobs:
deploy-stack:
name: Deploy Infrastructure
runs-on: ubuntu-20.04
permissions:
id-token: write
contents: read
steps:
... # other steps
- name: Deploy Routes stack
id: routes-stack
run: $GITHUB_WORKSPACE/cf-routes-stack.sh
- name: Deploy Routes application
if: ${{ env.CHANGES_APPLIED == '1' }}
id: routes-application
uses: actions/github-script@v6
with:
github-token: ${{ secrets.ACTIONS_PERSONAL_ACCESS_TOKEN }}
script: |
await github.rest.actions.createWorkflowDispatch({
owner: 'GitHub account',
repo: 'aws-route-lambda',
workflow_id: 'deploy.yaml',
ref: 'main'
})
... # other steps
From the previous snippet, when the environment variable CHANGES_APPLIED is set by the script cf-routes-stack.sh because a infrastructure change happened, the downstream route service is re-deployed to make sure it’s compliant with the new infrastructure.
Authorization Service
As mentioned earlier, Cognito was selected to provide authentication and authorization. I configured it to allow signup through local account or through an external identity provider (e.g.: Google). I also configured a custom oauth domain through Route53 and Cognito User Pool CloudFront distribution to standardize the authorization URL. However some issues showed up during this configuration to obtain the CloudFront domain (more details here and here).
The front-end developed React uses the Amplify library from AWS because it provides an implementation to integrate with Cognito. The following snippet show details about the required dependencies:
{
...
"dependencies": {
"@aws-amplify/ui-react": "^2.6.1",
"aws-amplify": "^4.3.14",
...
},
...
}
To integrate Amplify, React, and Cognito, the following configuration was made as part of the App.js file:
import './App.css';
import React, { useEffect, useState } from 'react';
import Amplify, { Auth, Hub } from 'aws-amplify';
...
const isLocalhost = window.location.hostname.includes("localhost");
Amplify.configure({
Auth: {
region: `${process.env.REACT_APP_AWS_OAUTH_REGION}`,
userPoolId: `${process.env.REACT_APP_AWS_OAUTH_USERPOOLID}`,
userPoolWebClientId: `${process.env.REACT_APP_AWS_OAUTH_USERPOOLWEBCLIENTID}`,
identityPoolId: `${process.env.REACT_APP_AWS_OAUTH_IDENTITYPOOLID}`,
oauth: {
domain: 'oauth.joaopedroschmitt.click',
scope: [
'phone',
'email',
'profile',
'openid',
'aws.cognito.signin.user.admin',
'api.joaopedroschmitt.click/addresses.read',
'api.joaopedroschmitt.click/routes.read',
'api.joaopedroschmitt.click/routes.write'
],
redirectSignIn: isLocalhost ? 'http://localhost:3000' : 'https://joaopedroschmitt.click',
redirectSignOut: isLocalhost ? 'http://localhost:3000' : 'https://joaopedroschmitt.click',
responseType: 'code'
}
}
});
function App() {
const [user, setUser] = useState(null);
useEffect(() => {
const unsubscribe = Hub.listen("auth", ({ payload: { event, data } }) => {
switch (event) {
case "signIn":
setUser(data);
break;
case "signOut":
setUser(null);
break;
default:
break;
}
});
Auth.currentAuthenticatedUser()
.then(currentUser => setUser(currentUser))
.catch(() => console.log("Not signed in"));
return unsubscribe;
}, []);
return (
<Layout style={{ minHeight: "100vh" }}>
<NavBar
isLogged={!!user}
email={user?.attributes?.email}
signIn={() => Auth.federatedSignIn()}
signOut={() => Auth.signOut()}>
...
</NavBar>
...
</Layout>
);
}
export default App;
With this global Auth object, I can program the front-end to get the JWT token from OAuth and pass it as part of the HTTP requests.
You can see an example at the snippet below:
Auth.currentSession().then(res =>
fetch(`https://api.joaopedroschmitt.click/routes/create`, {
method: 'POST',
headers: {
...
"Authorization": res.getAccessToken().getJwtToken()
},
body: JSON.stringify(routeDTO)
})
...
Address Service
The AddressService intends to find geographical coordinates for a given search string.
The geographical coordinates are required by the OptimizerService to calculate the distance matrix.
This service shows up when an user is editing a route (Logical Design section, Step 2).
For every address typed in the address input field, the front-end calls the AddressService to obtain a list of possible locations and their coordinates.
The image below presents an example of this use-case for the query “new york”.
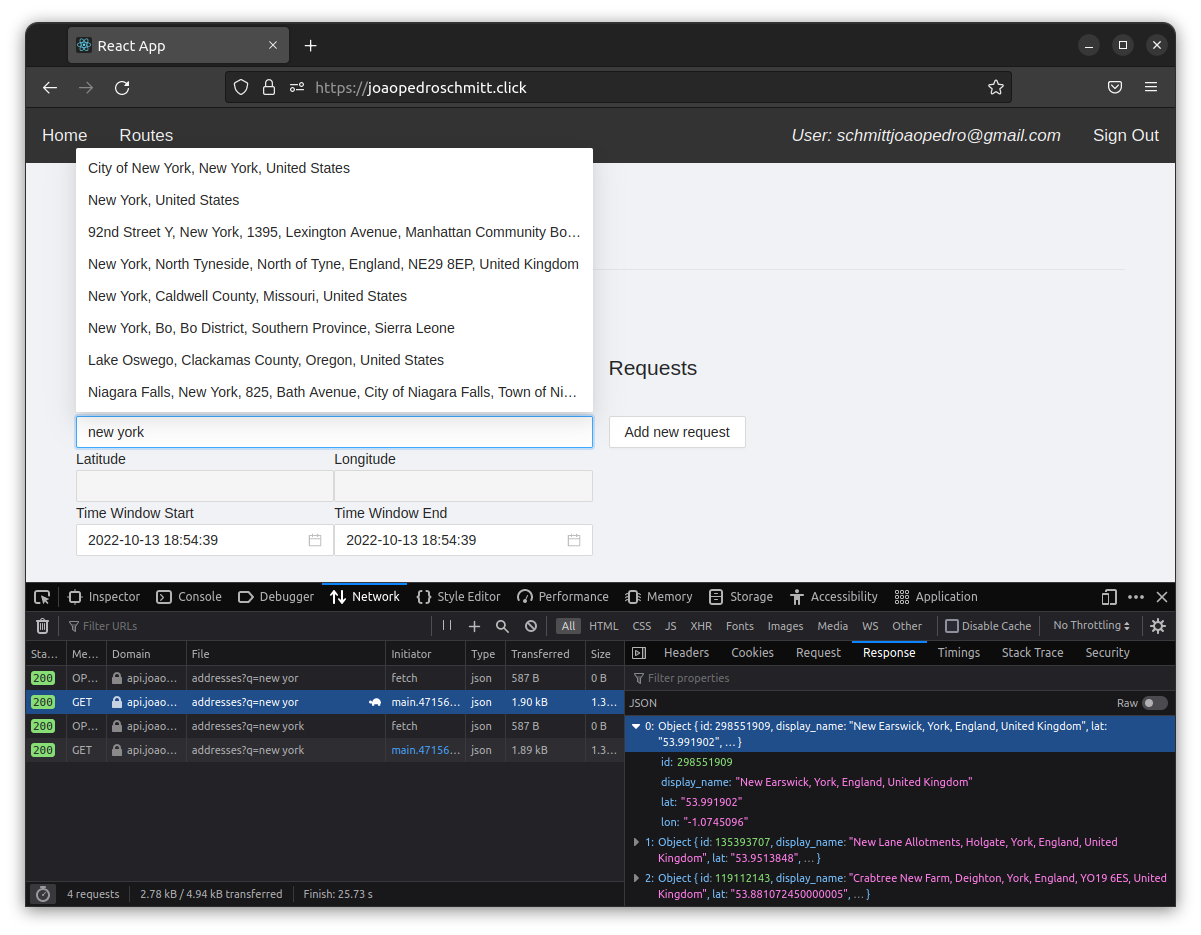
Behind the scenes AddressService calls the OpenStreetMap API to obtain location data.
There are many other external providers of such services, like Google Maps.
However, the advantage of OpenStreetMaps is that it’s free.
In essence the AddressService works as an anti-corruption layer between the front-end and the external provider.
It basically protects the frond-end from re-work in case we decide to change the external provider as long as the response from the provider can be transformed to the same format.
The general system architecture for the AddressService is composed of an AWS API Gateway integrated to Cognito and Lambda.
The API Gateway communicates to Cognito to authorize the front-end requests using the JWT token sent through the Authorization header.
The AWS Lambda function developed in JavaScript calls OpenStreetMap to transform the query response to the format expected by the front-end.
The Lambda function is developed in JavaScript because this function is small and the JS platform provides fast cold-start.
Route Service
The RouteService enables users to configure routes and also act as a facade for the OptimizerService.
Its main responsabilities are:
- persist routes for users in durable storage
- run business validations before saving a route
- invoke the optimizer service passing only the required information
- provide well-formatted itinerary details
- restrict user access so they can only see their owned routes
In terms of persistence I decided on DynamoDB as the RouteService database.
The motivation was due to its pay for what you use billing schema.
This way I don’t need to pay for a running RDS instance when the service is idle.
The route table presented below enables schema flexibility and quick retrieval of user’s routes.
The ID attribute is a random UUID value to minimize hot-partitioning issues.
The attributes createdAt, createdBy, and email, enables to associate, serach and recover routes to its owner users (these attributes are indexed).
Finally, depot and requests fields are JSON objects with the details about the route and used to generate itinerary with the OptimizerService.
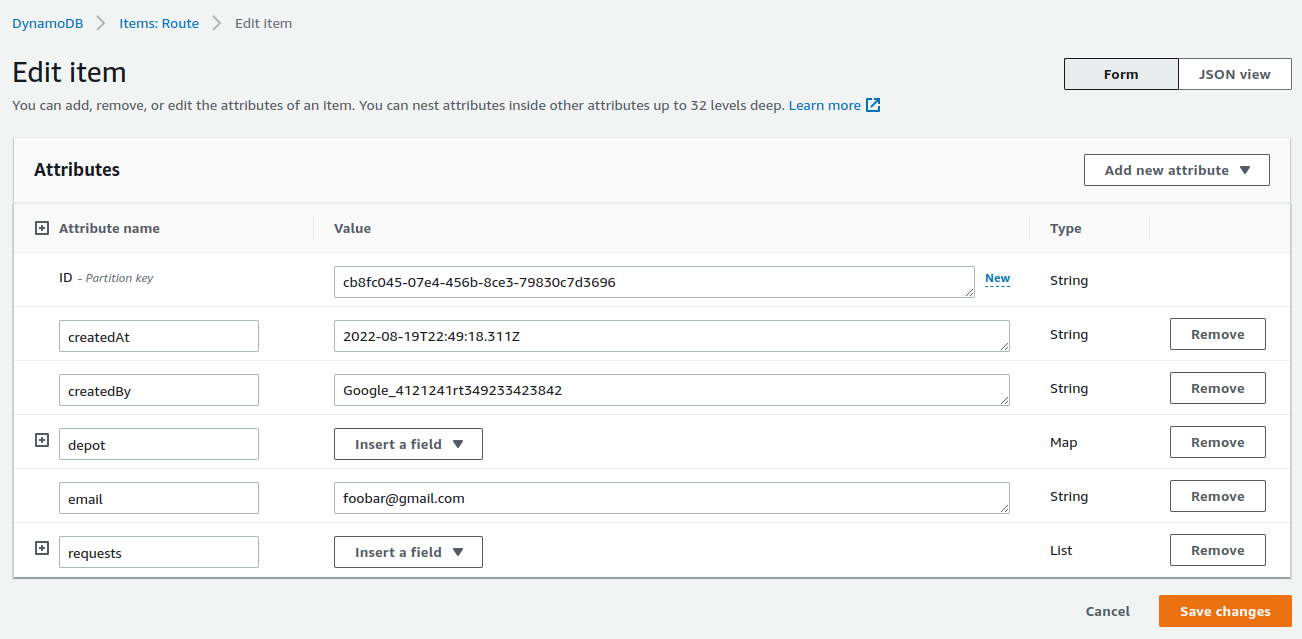
For a while the current schema is not an issue in terms of storage capacity (400KB max record size), but in the future we may need a different strategy using S3 to persist routes if this limit is not enough anymore.
The same way as the AddressService, the RouteService runs on top of AWS Lambda.
This decision saves costs because we only pay for what we use.
The Lambda function is accessed through API Gateway as all requests are authorized by validating the JWT token with Cognito.
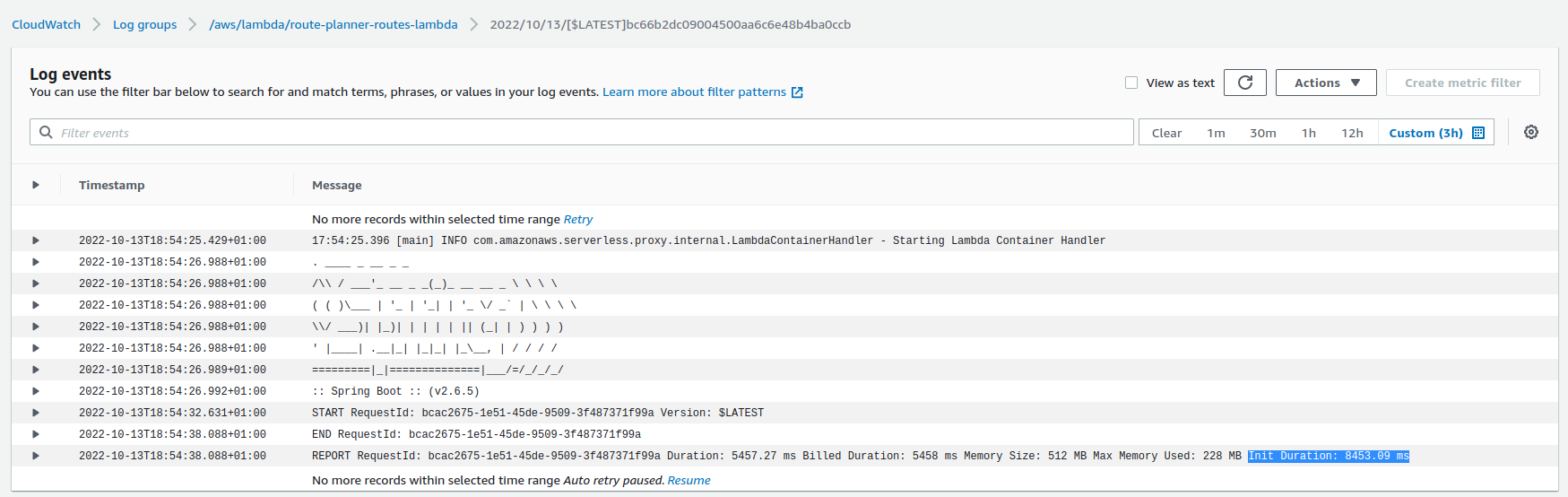
The tech-stack chosen for this service was mainly Spring-Boot due to the experience with the framework and because I could reuse code from a previous project. However, this service is strugling with cold starts because Spring takes more than 10 seconds to start serving requests. For example, the logs from the image below shows the cold-start issue due to the time taken to initialize the function (~8.4 seconds). For the long term, I think it could be a good idea to migrate the service to either Quarkus Native or GoLang.
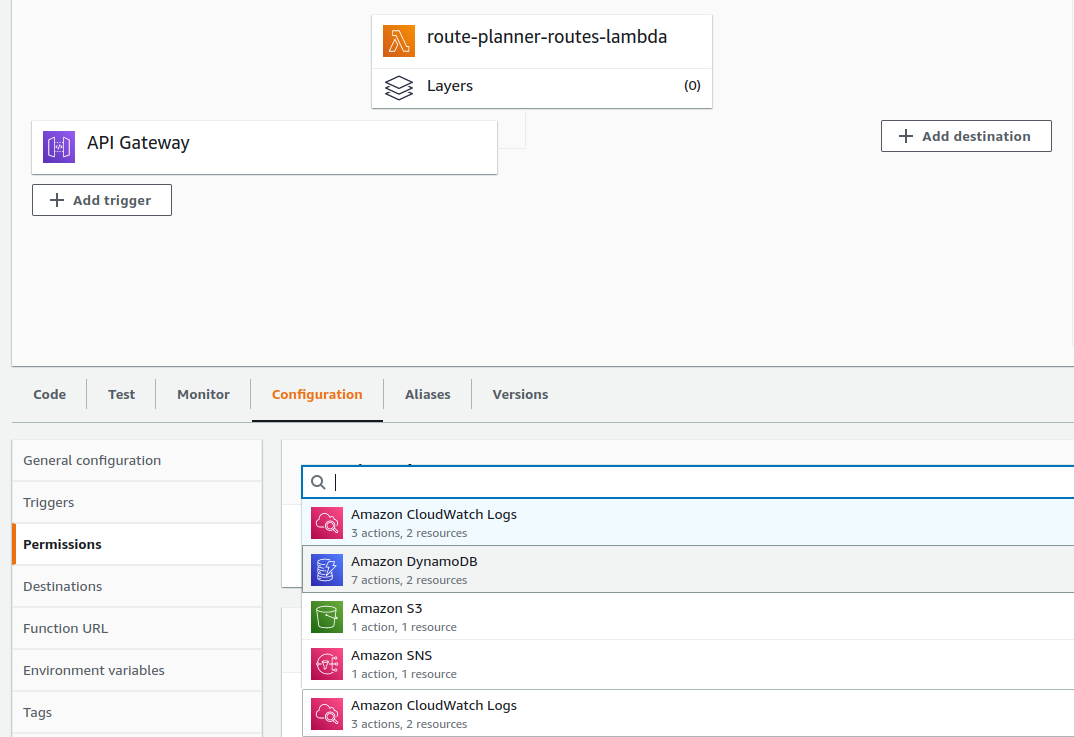
This service integrates with a couple of AWS services.
It persists data into DynamoDB and sends messages to OptimizerService by persisting the route JSON files into S3 and notifying the OrchestratorService through SNS.
All these integrations are done using AWS SDK and permissions to the services are granted through a single AWS Role linked to this function.
The image below gives a general glance about the function.
Optimizer Service
The SolverService is the most complex of all services.
It implements an AI solution to find the best itinerary for a given route (see section Vehicle Routing Problem for more details).
Because the solver was developed in Java, and Java is not a good fit for Lambda functions, I decided to go with Quarkus Native due to its smaller startup times, less memory consumption, and mainly because I wouldn’t need to rewrite the whole solver in another language.
AWS Lambda function doesn’t support Quarkus Native executions by default, so a custom Lambda extension was required $^3$.
You can see more details about Quarkus Native to AWS using Github Actions here.
The trade-off with Quarkus Native and other languages is its compilation time, it takes a few minutes to generate the final binary and therefore requires more computation during the build.
However, once the build is done and deployed, Quarkus Native in Lambda functions run very well.
They have little initalization time and are very efficient in terms of memory consumption.
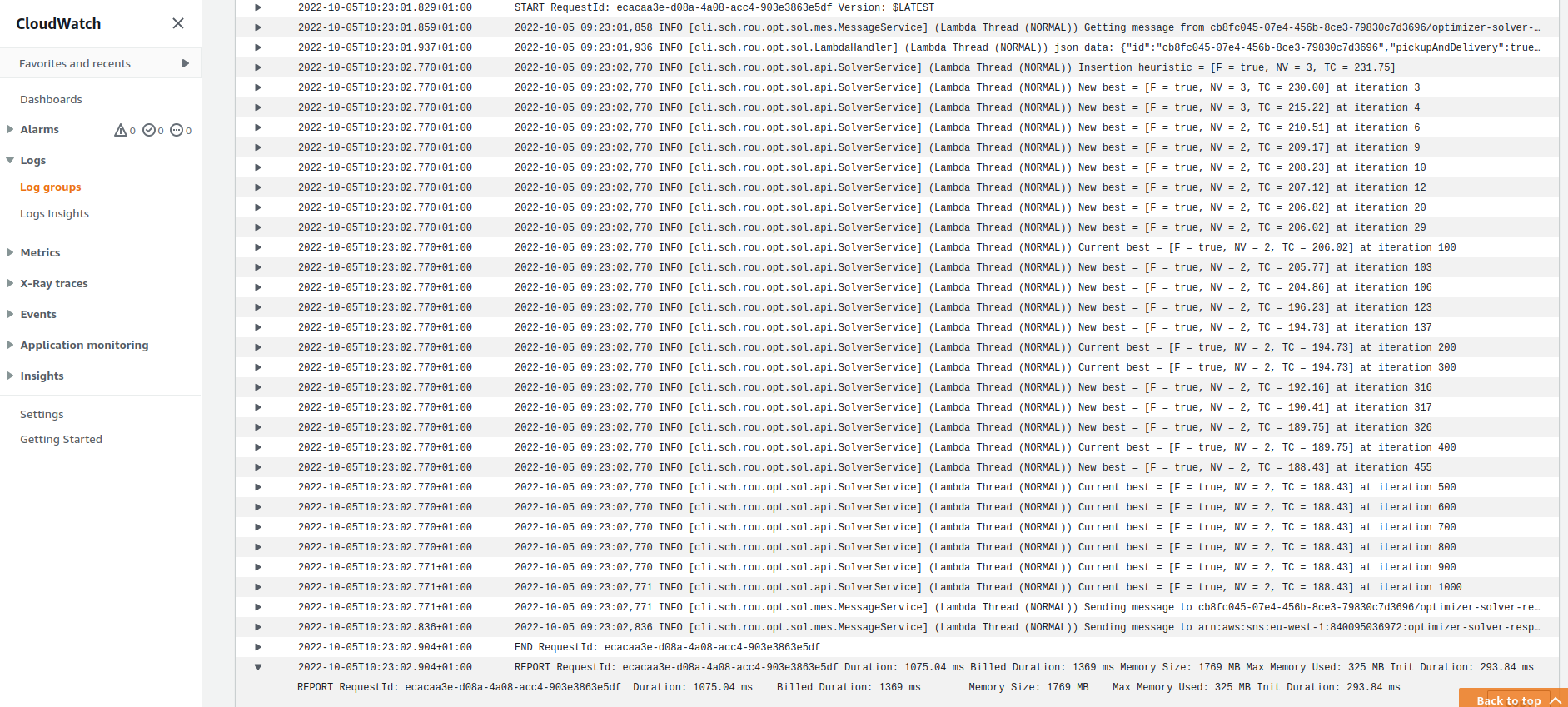
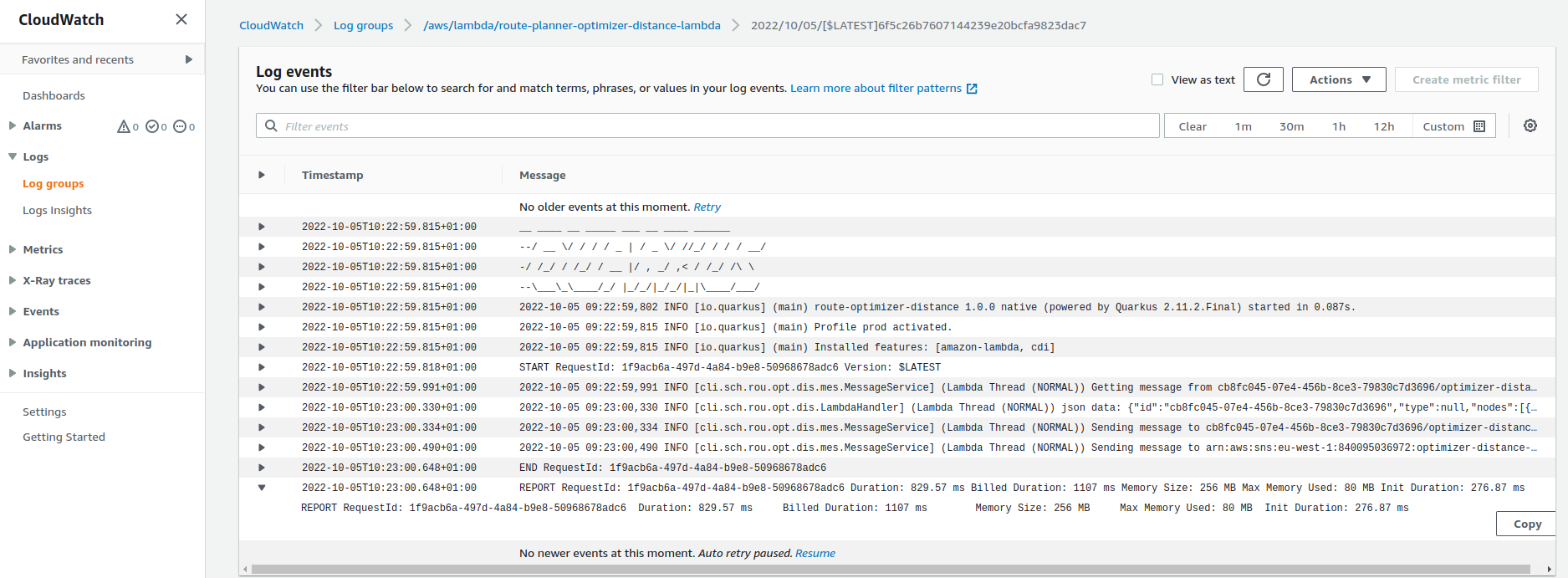
The image below shows the logs for a single lambda execution of the SolverService.
Notice that the total time required to instantiate the solver took less than 300ms, and the execution consumed 325MB of memory.
Besides that, in the same image you can also see the log details of the solving process.
Every time a new best solution (a.k.a. itinerary) is found the solver reports it in the logs.
Because the SolverService is a heavy service, as it consumes a lot of CPU, then I set up the Lambda function to use 1.7GB of memory RAM so a complete CPU is available to run the code in the most efficient way possible.
This solver algorithm doesn’t benefit from multiple threads so I don’t need more than one CPU.
The OrchestratorService and DistanceService are simple algorithms compared to the SolverService.
They also require way less hardware resources.
So you can have an idea, the following image shows the logs for the DistanceService after responding a request to calculate the distance matrix for a route.
You can see from this execution that the initalization time was around the same as the previous SolverService but the memory consumed was smaller, around 80MB.
All three services that compose the OptimizationService communicate asynchronously through messages.
For this project I decided on SNS as the communication tool because it doesn’t require frequent pooling to fetch the messages (like in SQS), so in theory we should save some costs.
SNS was combined with S3 to send the payload from point A to B.
SNS only supports messages up to 256Kb, and most payloads overpass this limit, then I use S3 to store the messages.
The way it works it simple, every time service A wants to send a message to service B, service A persists the message in S3 with a key prefix value equal to the route ID to be optimized.
Then service A sends an SNS message notification with the S3 key as part of its message body.
When service B receives the notification, it fetches the content by opening up the payload from the given key in S3.
General Performance Analysis
Address Service Performance
In order to validate the performance and scalability of AddressService a load test was performed.
I used Gatling as the testing framework for this task.
You can see the simulation details in the snippet below.
This test scenario queries the AddressService by passing different query values, and expects the response to be sucessfull.
class AddressServiceSimulation extends Simulation {
val feeder = csv("data/search.csv").random
val search = {
feed(feeder)
.exec(
http("Search Address")
.get("/addresses")
.queryParam("q", "#{searchCriterion}")
.check(
status.is(200),
jsonPath("$[*].id").count.gt(0)
)
)
}
val httpProtocol = http.baseUrl(Configuration.apiURL)
.authorizationHeader(Configuration.accessToken)
var users = scenario("Users").exec(search)
setUp(
users.inject(
constantUsersPerSec(10).during(5.minutes)
//constantUsersPerSec(50).during(5.minutes)
//constantUsersPerSec(100).during(5.minutes)
)
)
.protocols(httpProtocol)
.assertions(
global.successfulRequests.percent.gt(99)
)
}
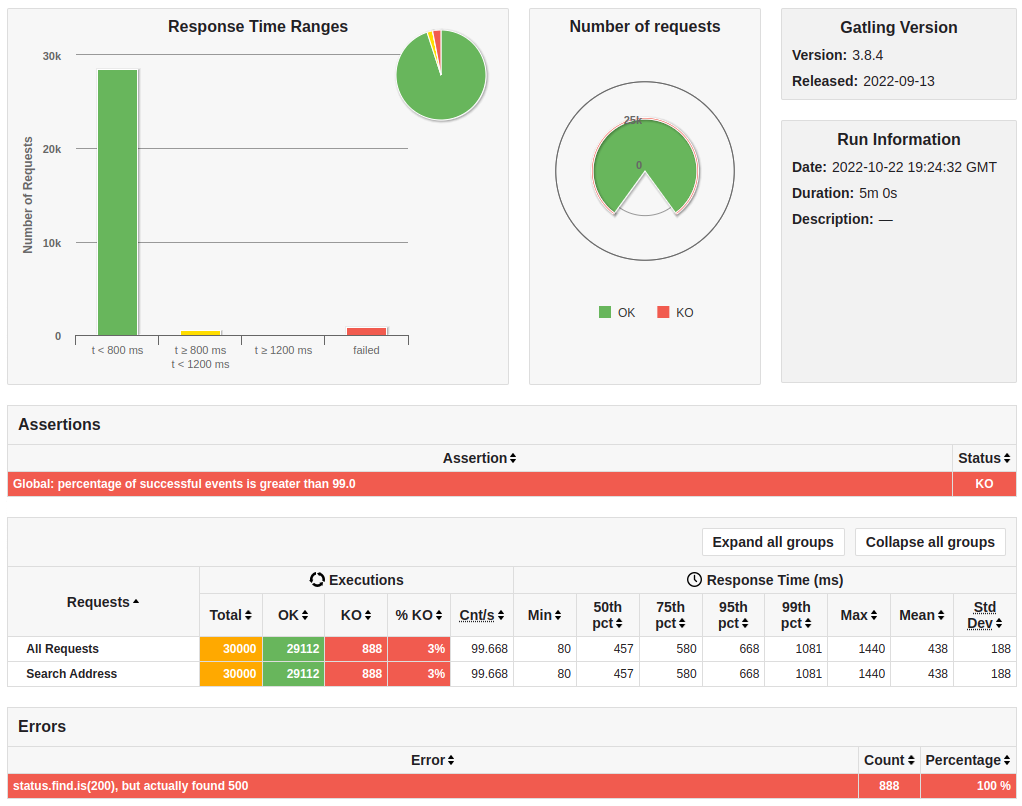
The system was loaded up until the point it started to fail. It happened when the simulation reached 100 users per second. You can see at the image below that roughly 3% of all requests failed with 500 status code.
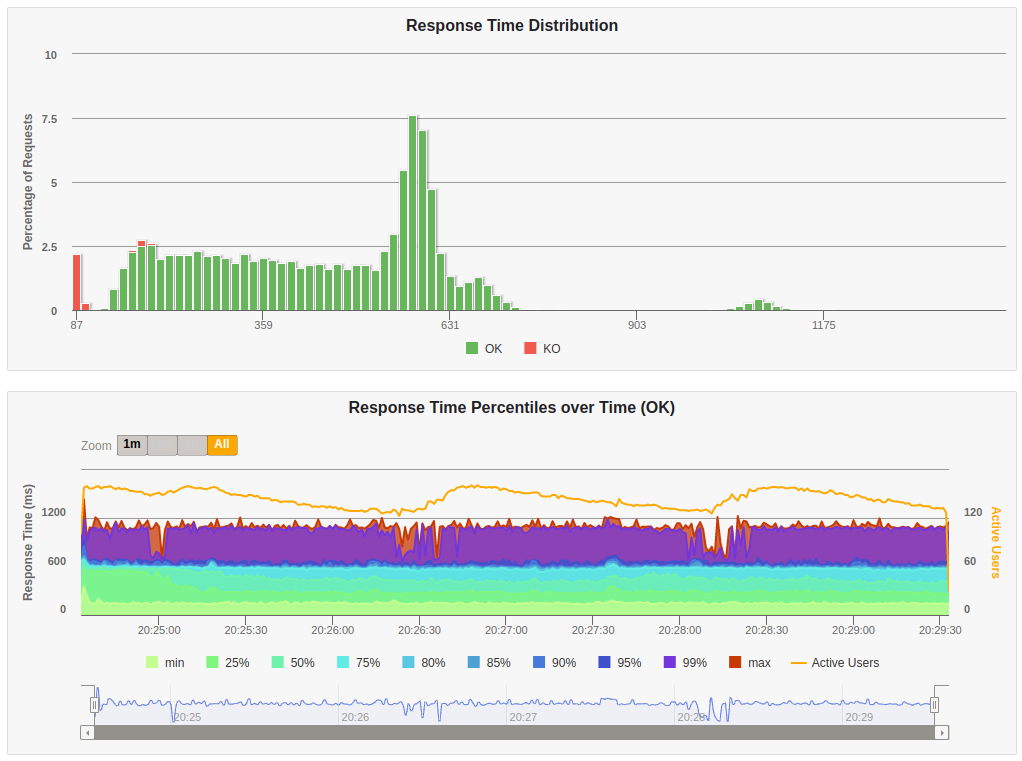
The graph below shows that 95% of all requests took less than 700ms to get a response from the server (including network round-trips between Portugal and Ireland). Lambda functions take some time to start responding requests, this issue is known as cold-start issue. We can see the cold-start by looking at the beginning of the graph where there’s a small spike on the response times.
The failed requests observed above were probably affected by the Throttling applied during the simulation (the following graph shows around 180 throttles). The “Response Time Distribution” at the previous graph shows that it takes less than 200ms to fail a request, that’s coherent with the throttling type of error when a request fails before getting to the back-end service. In terms of resources consumption we can see that around 50 lambda functions instantiated to hold the load. It reasons with the observed time of ~600ms where within each second we have 100 users making requests to the back-end, and therefore it takes roughly one lambda function to respond two users.
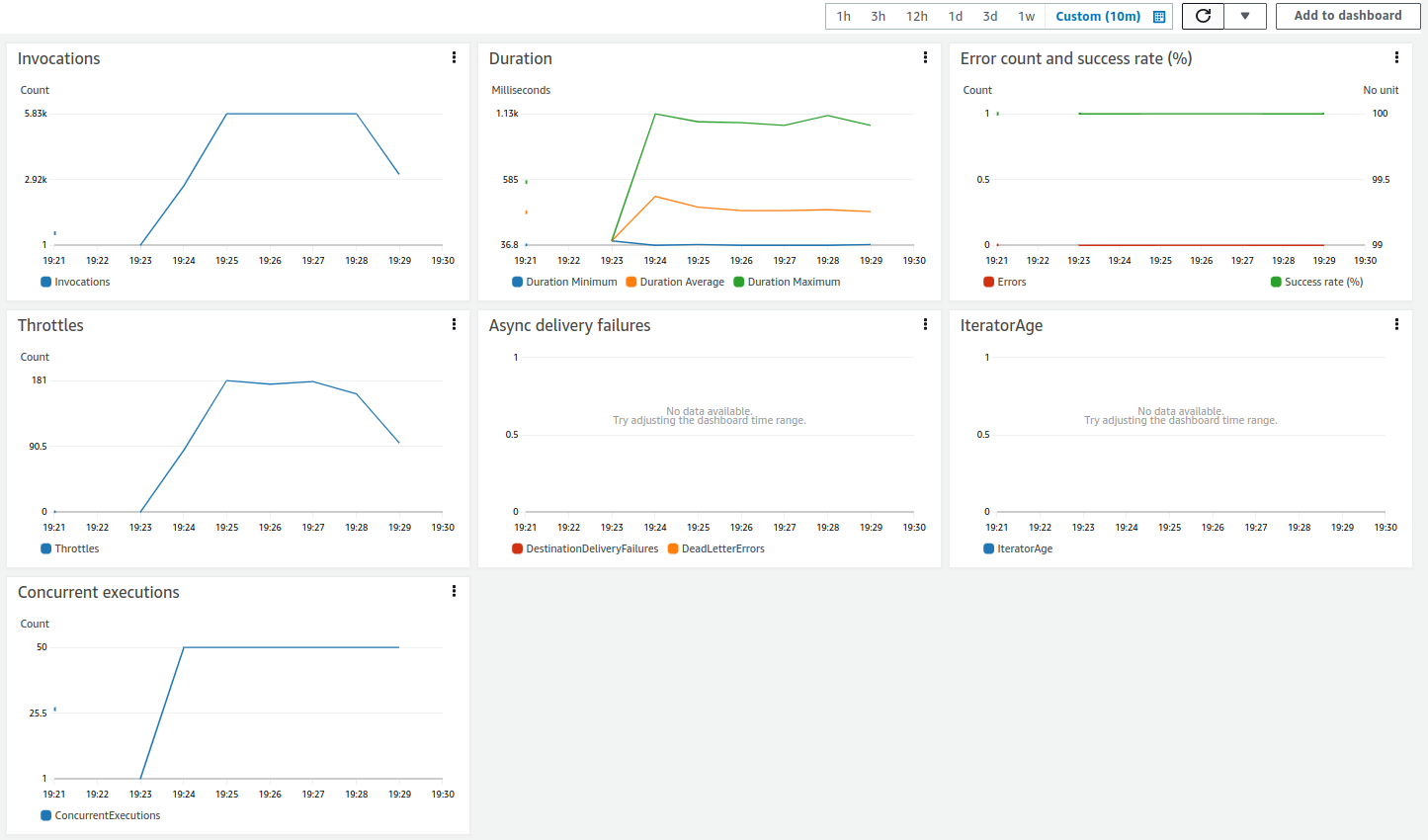
This service is quite performant and scalable given we reached it’s limitation by a throttling configuration that could be increased to enable more load.
Route Service Performance
As mentioned earlier, the RouteService was developed in Spring Boot as per the official documentation.
The goal of this performance test was to validate the complete end-to-end flow composed by the scenarios of creating, listing and loading a route.
The following code snippet presents the script developed in Gatling to run this simulation.
class RouteServiceSimulation extends Simulation {
val feeder = csv("data/address.csv").random
var create = feed(feeder)
.exec(
http("Create Route")
.post("/routes/create")
.header("Content-Type", "application/json;charset=UTF-8")
.body(RawFileBody("#{payloadPath}"))
.check(
status.is(200),
jsonPath("$.id").saveAs("routeId")
)
)
.exec(
http("Find all Routes")
.get(s"""/routes/createdby/${Configuration.userId}""")
.check(
status.is(200),
jsonPath("$[*].id").count.gt(0)
)
)
.exec(
http("Find Route by ID")
.get("/routes/find/#{routeId}")
.check(
status.is(200),
jsonPath("$.id").is("#{routeId}")
)
)
val httpProtocol = http.baseUrl(Configuration.apiURL)
.authorizationHeader(Configuration.accessToken)
val users = scenario("Users").exec(create)
setUp(
users.inject(
//constantUsersPerSec(1).during(5.minutes)
//constantUsersPerSec(2).during(5.minutes)
constantUsersPerSec(4).during(5.minutes)
)
)
.protocols(httpProtocol)
.assertions(global.successfulRequests.percent.gt(99))
}
Because this service runs with the standard Spring Boot framework, we expect it to struggle to scale due to its slow startup time. Due to this reason, I started the simulation by setting lower load parameters. The graph below presents the results for worst case simulation with four users per second.
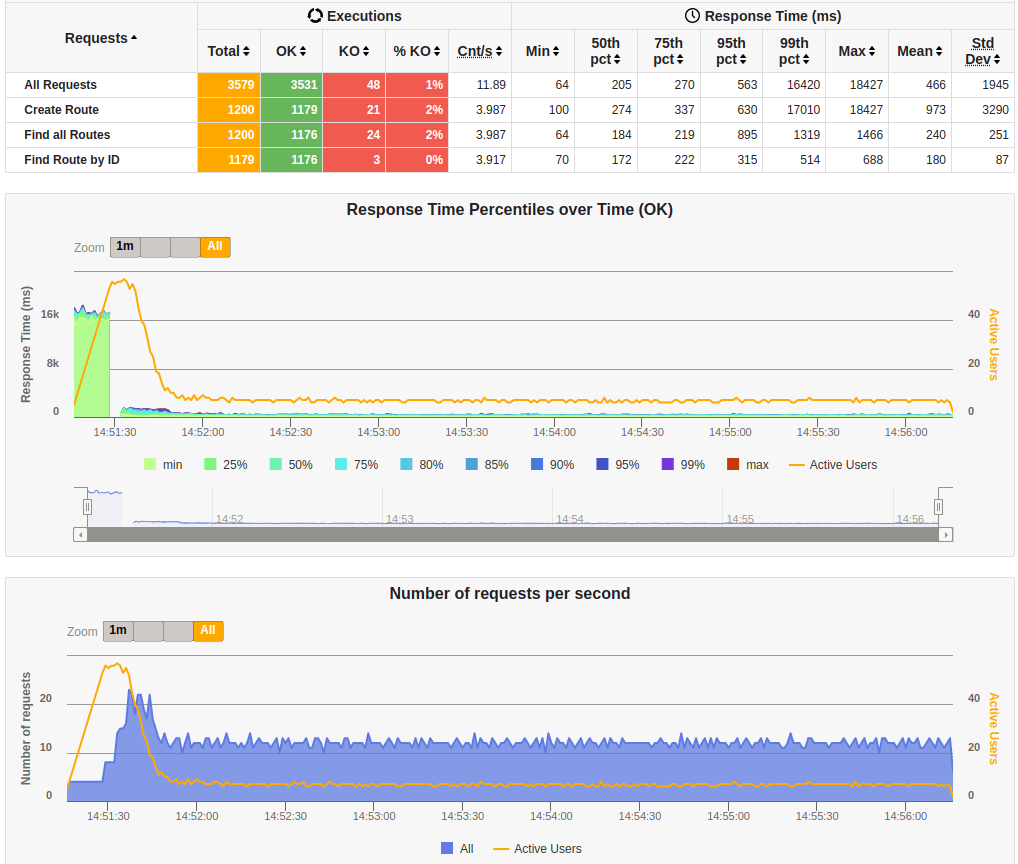
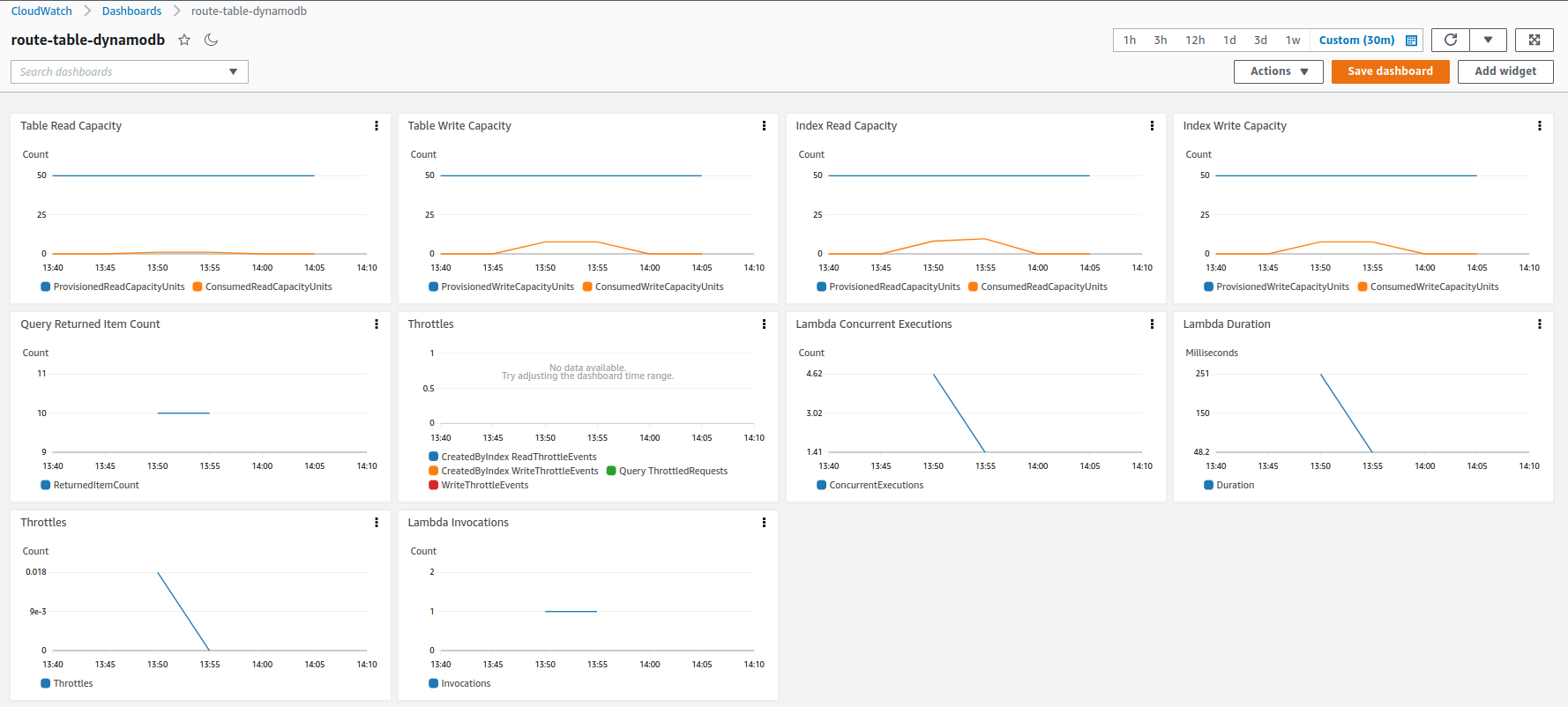
In terms of error rate, we can see that around 1% of all requests failed. I didn’t dig deep enough to find the root cause, but I suspect from cold-start as the service currently takes ~16sec to start. In this simulation a load of four users per second during 16 secs yields 64 concurrent lambda functions until the first request is served. Besides that DynamoDB was configured to 50 WCU, so it supports at maximum 50KB of writting data per second. Because each create route request saves around 8KB of data, the current DynamoDB configuration supports a peek of ~6 requests per second. Therefore I hyphotesize that DynamoDB throttled some connections at some point and caused the errors observed. By looking the CloudWatch I couldn’t see any throttling on the DynamoDB reports, but I saw a few on the Lambda reports. Maybe the data feed wasn’t granular enough to see the throttling on DynamoDB side, as there’s only one measurement every 5 minutes. The following graph shows the metrics collected during the simulation from CloudWatch.
In terms of performance, we can see the impact of cold start by looking at all graphs from the previous image. The 95th percentile for the first request was less than 1sec, and the 99th percentile was around 17secs. The time taken to warm up the Lambda function by looking the graph “Response Time Percentiles” shows that the first 20 seconds of the simulation took more time to start responding requests than the remaining of the simulation. It shows that the first requests to hit the Lambda function were queued until their responses were computed (active users almost reached 60). The side effect is a bunch of Lambda functions being created to handle the initial load, and after the cold-start period has ended, the number of lambda functions start decreasing to the expected rate of ~5 users per second. It’s interesting to see how Lambda is able to handle the cold-start by dynamically instantiating more functions. However, unfortunately, all inital queued users are spilled over at some point to DynamoDB when they all are served by the finally warmed Lambda functions. As already mentioned, DynamoDB was limited to 6 reqs/sec, and hence it is wasn’t tuned to smootly couple with this load of requests.
Optimizer Service Performance
The OptimizerService is composed of three micro-services that communicate asynchronously through SNS.
The load test conducted for this service used Gatling merelly to bulk load messages to the OrchestratorService.
In this case I didn’t program to request the optimization through the RouteService to prevent any skewed results due to the poor performance of RouteService observed in the previous experiment.
However, because Gatling doesn’t support AWS protocols natively, I only used the framework to load the messages into AWS, so reports are not available.
The snippet of code below shows how this simulation was conducted.
class OptimizerServiceSimulation extends Simulation {
val fileContent = Source
.fromResource("data/optimizer-request.json")
.mkString
val s3Client = S3Client
.builder()
.httpClient(UrlConnectionHttpClient.builder().build())
.build()
val snsClient = SnsClient
.builder()
.httpClient(UrlConnectionHttpClient.builder().build())
.build()
val search = {
exec { session =>
val routeId = UUID.randomUUID().toString()
// Upload message to S3
s3Client.putObject(PutObjectRequest
.builder()
.bucket("schmittjoaopedro-click-route-planner-optimizer")
.key(s"""${routeId}/optimizer-orchestrator-request.json""")
.build(),
RequestBody.fromString(fileContent.replaceAll("#route_id#", routeId))
)
// Request optimization through SNS
val attributes = new util.HashMap[String, MessageAttributeValue]()
attributes.put("routeId", MessageAttributeValue.builder()
.dataType("String")
.stringValue(routeId)
.build())
attributes.put("messageType", MessageAttributeValue.builder()
.dataType("String")
.stringValue("optimizer-orchestrator-request")
.build())
snsClient.publish(PublishRequest
.builder()
.message(s"""${routeId}/optimizer-orchestrator-request""")
.topicArn(Configuration.topicArn)
.messageAttributes(attributes)
.build()
)
session
}
}
val httpProtocol = http.baseUrl(Configuration.apiURL)
.authorizationHeader(Configuration.accessToken)
var users = scenario("Users").exec(search)
setUp(
users.inject(
//atOnceUsers(10)
//atOnceUsers(100)
atOnceUsers(1000)
)
)
.protocols(httpProtocol)
}
The OrchestratorService service communicates with DistanceService and SolverService, and because it requires more throughput to support all communication, it’s a good candidate to analyse the metrics.
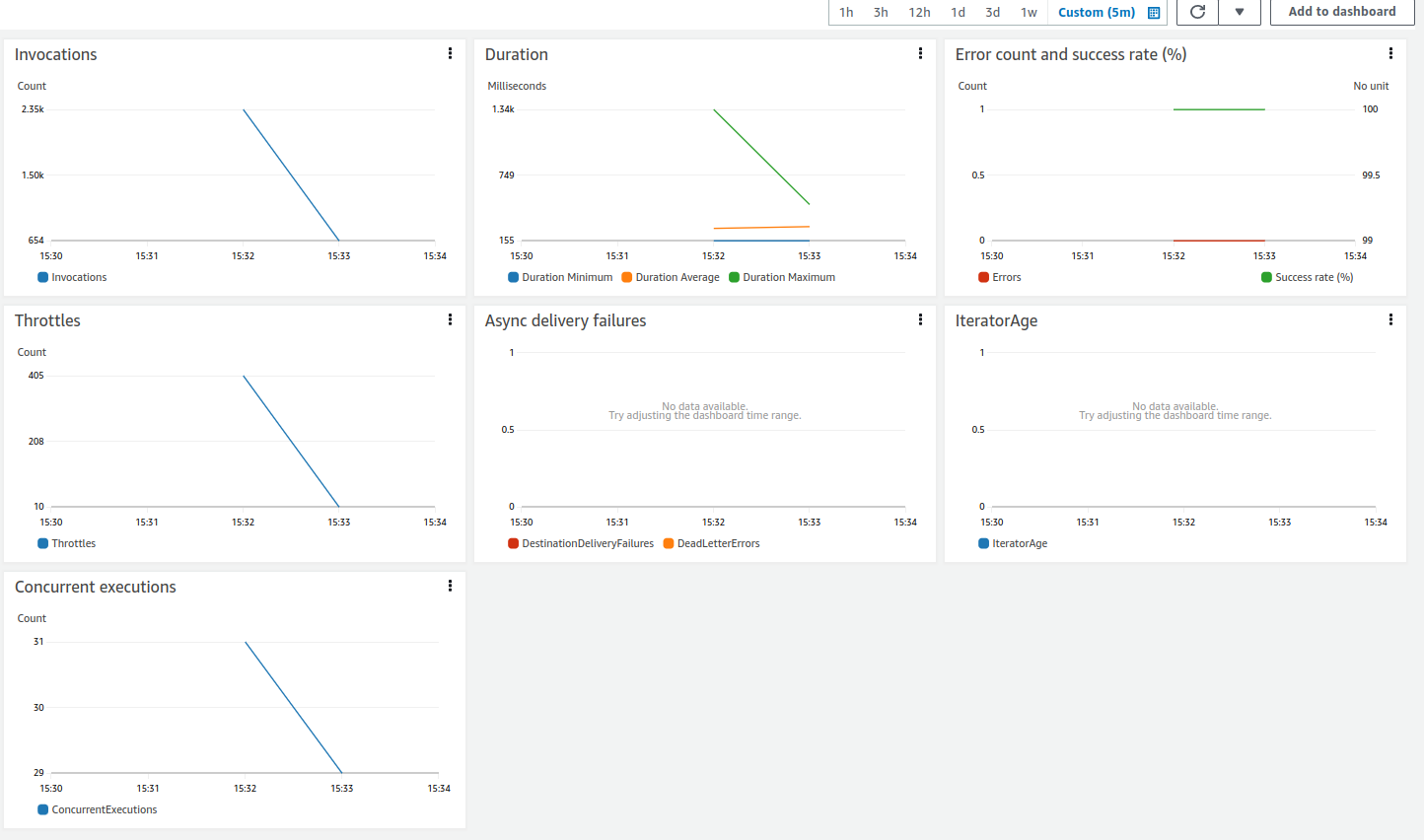
We can see the main metrics collected from AWS in the image below.
The following graph shows results obtained from the simulation with 1000 thousand optimization requests.
The graphs aren’t granular enough to get precise information about the metrics, but from the information provided we can see that more than 2k invocations happened to this service during the period of 5 minutes.
Although some throttling was also recorded, I couldn’t find any missing itinerary by analysing the final messages sent out from the service.
It’s probably due to the SNS retry policy.
When Lambda throttles, SNS service backs off for some time and try again later until it succeeds or reaches the maximum number of retries.
In this case, the service was capable of dealing with a load of 1K messages during 5 minutes, it corresponds to 3 requests per second.
References
[1] Wikipedia - Vehicle Routing Problem. Available at: https://en.wikipedia.org/wiki/Vehicle_routing_problem
[2] TERMHIGEN-A Hybrid Metaheuristic Technique for Solving Large-Scale Vehicle Routing Problem with Time Windows. Available at: https://www.researchgate.net/figure/Description-of-a-Multi-Node-Vehicle-Routing-Problem-35_fig1_331408676
[3] Quarkus Native on AWS Lambda functions. Available at: https://quarkus.io/guides/amazon-lambda